这里不介绍 Claude Code 的基本使用,仅讨论使用 Claude Code 过程中可能涉及到的各种工具,比如怎么让模型输出的代码符合团队的代码规范,怎么理解和使用 Skills,怎么创建自定义命令以及怎么创建 sub-agents 等,内容还是比较简单的。
首先要记住:
- 模型的输出质量很大程度上取决于输入的质量
- 上下文越长,模型输出质量越差
CLAUDE.md & AGENTS.md
通常,我们应该在项目根目录创建 CLAUDE.md 文件,它简单描述这个项目的结构、技术栈等。Claude Code 会在每次会话的时候,自动将 CLAUDE.md 的文件内容发送出去,所以这个文件不宜太大,通常 100-200 行即可,比如代码规范或者 Redis 使用规范这种内容,就不适合放在这里。
对于现有项目,最好的使用方式是使用 /init 命令,它会分析项目代码,然后生成 CLAUDE.md 的初始版本。通常这个文件的内容都不会太长,主要就是介绍整体的架构、技术栈、核心模块组织方式等。
CLAUDE.md 只能给 Claude Code 使用,其他的 AI 工具不会自动使用它,比如 Cursor、Codex 等,如果团队中有人用其他工具,那么最好的方式就是统一维护内容在 AGENTS.md 中。这种情况下也推荐创建 CLAUDE.md 文件,但是它的内容就可以非常简单,只是告诉 Claude Code 去读 AGENTS.md 文件:
详见 @AGENTS.mdCLAUDE.md 和 AGENTS.md 都是放在项目的根目录中。
另外,我们也可以设置用户级别的 CLAUDE.md,放在 ~/.claude/CLAUDE.md,它影响所有的会话。
在项目子目录中,也是可以放置 CLAUDE.md 的,这种就不是 Claude Code 启动的时候自动读取的,它会在 Claude Code 读取对应的目录的时候,如果发现有这个文件,自动加载进来,通常我们可以用它来描述某个 package 下面的代码需要遵守的一些规则。
Skills
Skills 最早就是 Claude 提出来的,它旨在减少 token 的使用,保证模型输出的内容质量,因为它是按需加载到 context 中的。
Skills 分全局的和当前项目的:
~/.claude/skills/ # 全局 skill,所有项目可用,放在用户目录的 .claude/skills 目录下
└── spring-security/
├── SKILL.md
.claude/skills/ # 项目 skill,仅当前项目,放在当前项目的 .claude/skills 目录下
└── kafka-producer/
└── SKILL.md这个目录结构很清晰,skills 目录下,创建子目录,每个子目录代表一个 skill。
每个 skill 最重要的是子目录中的 SKILL.md 这个描述文件,它的开头非常重要,要描述清楚这个 skill 在什么场景下需要让模型加载整个文件的内容:
---
name: redis-specification
description: 如果需要使用 redis,需要遵守这个文件描述的Redis规范以及最佳实践
tags: [redis, performance]
---
# 目的
只有在使用 Redis 的时候,这个文件的规范才是必须的。
# Redis 使用规范
请使用 RedisTemplate 和 StringRedisTemplate 来完成......我们要理解 skills 必须回到它的设计初衷,它是为了解决上下文太长导致模型输出质量下降的问题。SKILL.md 的开头部分,其实就是“索引”,这部分内容固定会发送给大模型,大模型会根据实际情况,决定是否要加载整个文件内容。
其实就相当于一本书的目录,大模型一看这个目录,大概就知道这个书是不是要读。因为书的内容可能很长,但是看一下目录还是可以的。
实际使用过程中,我们就可以把团队中的各种代码规范、中间件使用最佳实践、各个模块的设计规范等做成一个个 skill 供模型使用。
这里要注意一点,作为开发代码所需要的 Skills,通常是组织内部的一些特殊规范,如果是那种所有人都知道的最佳实践,AI 比我们更懂,没必要画蛇添足,比如教 AI 怎么使用 Spring Kafka,AI 可比我们懂多了。如果你的团队在使用 Kafka 的时候,有 consumer group 的命名规范,比如一定要使用 {topicName}_{applicationName},这种个性化的配置适合作为 skills 的内容。
Rules
Update on: 2026-02-18 前面一小节介绍了 Skills,我觉得有必要简单提一下 Rules,因为它们有一些重叠。在 Skills 出来之前,Rules 可能是最适合用来管理代码规范或者是中间件使用最佳实践的地方。这里介绍它是怎么使用的,大家自己决定要不要用它。
.claude/rules/ 目录下可以放多个 Markdown 文件,每个文件描述一组规则,Claude Code 会在会话开始的时候自动加载它们:
.claude/rules/
├── java-code-style.md # Java 编码规范
├── api-design.md # API 设计规范
└── database.md # 数据库操作规范Rules 和 Skills 的区别就是,它始终生效,影响所有决策,无论是否需要都占用 context,所以我觉得它应该被 Skills 直接替代。
而对于一些强制项,比如安全红线、架构约束等,可以放 CLAUDE.md。
Slash Commands
在 Claude Code 中,敲一下斜杠 / 就会列出所有可用的命令,有时候,很多重复的工作,我们也可以做成命令,这样敲一下斜杠就可以用了,非常方便。比如可以搞一个 /code-review 这种命令,让大模型 review 新写的代码。
自定义命令和 Skills 一样,也可以定义全局的和项目独有的:
~/.claude/commands/ # 全局命令(所有项目可用)
├── code-review.md
└── bug-fix.md
.claude/commands/ # 项目命令(仅当前项目)
├── deploy-check.md
└── api-test.md至于这个 markdown 文件怎么写,那就随意了。
在实际实践中,你可以传递参数,也可以让模型主动询问你,得到你的回答以后再继续工作,取决于你在这个 markdown 文件中写的内容,比如下面是一个 /code-review 命令的例子:
<!-- ~/.claude/commands/code-review.md -->
对 $ARGUMENTS 进行全面的代码审查,检查:
1. 代码质量
- 是否遵循项目编码规范
- 命名是否清晰
- 代码复杂度是否合理
2. 潜在问题
- 空指针风险
- SQL 注入风险
- 并发安全问题
- 资源泄漏风险
3. 性能问题
- 不必要的循环
- 缓存使用建议
4. 最佳实践
- 事务边界是否合理
- 异常处理是否完善
- 日志记录是否充分
请提供具体的改进建议和代码示例。那么每次你觉得代码写得差不多了,准备提交了,就可以执行 /code-review。
Sub-agents
把 sub-agents 翻译成子代理其实不太好理解,所以我就保持使用这个英文单词不做翻译。
理解 sub-agents,我们需要知道 sub-agents 最核心的是,它有自己独立的提示词、独立的权限管理、独立的上下文、可以并行执行复杂任务。
这意味着,它不会污染主对话,进而导致主对话的质量下降。多个 agent 可以同时工作,减少我们的等待时间。
同样的,我们可以设置全局 agent 和项目级的 agent:
~/.claude/agents/ # 全局 agent
├── code-reviewer.md
└── test-writer.md
.claude/agents/ # 项目 agent
├── api-architect.md
└── performance-optimizer.md可以手动按照这个目录结构来创建 agent,也可以使用 Claude Code 提供的 /agent 命令,交互式创建 agent。
比如还是 code review 这个例子,我们搞一个 agent:
<!-- ~/.claude/agents/code-reviewer.md -->
---
name: code-reviewer
description: 专业代码审查员。审查代码质量、安全性和可维护性。在编写或修改代码后立即使用。
tools: Read, Grep, Glob, Bash
model: sonnet
---
你是一名资深代码审查专家,专注于 Spring Boot 项目。
## 审查流程
1. 运行 git 命令查看最近的修改: git diff HEAD
2. 聚焦修改的文件,不要审查未修改的代码
3. 检查项
- 代码质量: 可读性、复杂度、命名规范
- 安全问题: SQL 注入、XSS、敏感信息泄露
- 并发安全: 线程安全、事务边界
- 性能问题: 不必要的循环
- 最佳实践: Spring Boot 规范、设计模式
4. 输出格式
- 每个问题标注文件和行号
- 说明问题原因
- 提供修改建议
- 给出示例代码当然你也可以搞一些 agent 比如:
- test-engineer 这个 agent 负责写测试代码
- performance-optimizer 负责性能优化
- security-auditor 负责安全检查
通常来说,Claude Code 会自动在需要的时候触发 sub-agent,等它们执行完成以后,会给主会话返回工作结果。
当然我们也可以显式指定模型去执行对应的 agent,比如 code review 这个场景,显然模型不太可能知道什么时候该执行这个 agent 了,我们可以在会话中让模型去执行它:
> 请使用 code-reviewer 审查未提交的代码变更如果要多个 agent 并行执行,可以这样:
> 请并行启动以下 sub-agent,审查未提交的代码变更:
1. code-reviewer: 代码质量审查
2. security-auditor: 安全审查
3. performance-optimizer: 性能分析
等待所有 sub-agent 完成后汇总报告。总体来说,sub-agent 的能力可以很强,也可以专注在很小的一块,取决于你怎么定义它。通常不建议搞太细,agent 太多不好管理。
到这里,大家应该很容易理解,它为什么叫 sub-agents 了,因为主会话是一个 agent,它负责调度这些 sub-agents 来帮它处理一些杂活,它只需要知道执行结果就可以了,不希望被中间产生的大量 context 污染了自己的主要 context。
为 Claude Code 添加状态栏
add on 2026.03.17
为了更好地观测到上下文的消耗情况,大家可以稍微配置一下自己的 Claude Code,比如我的:
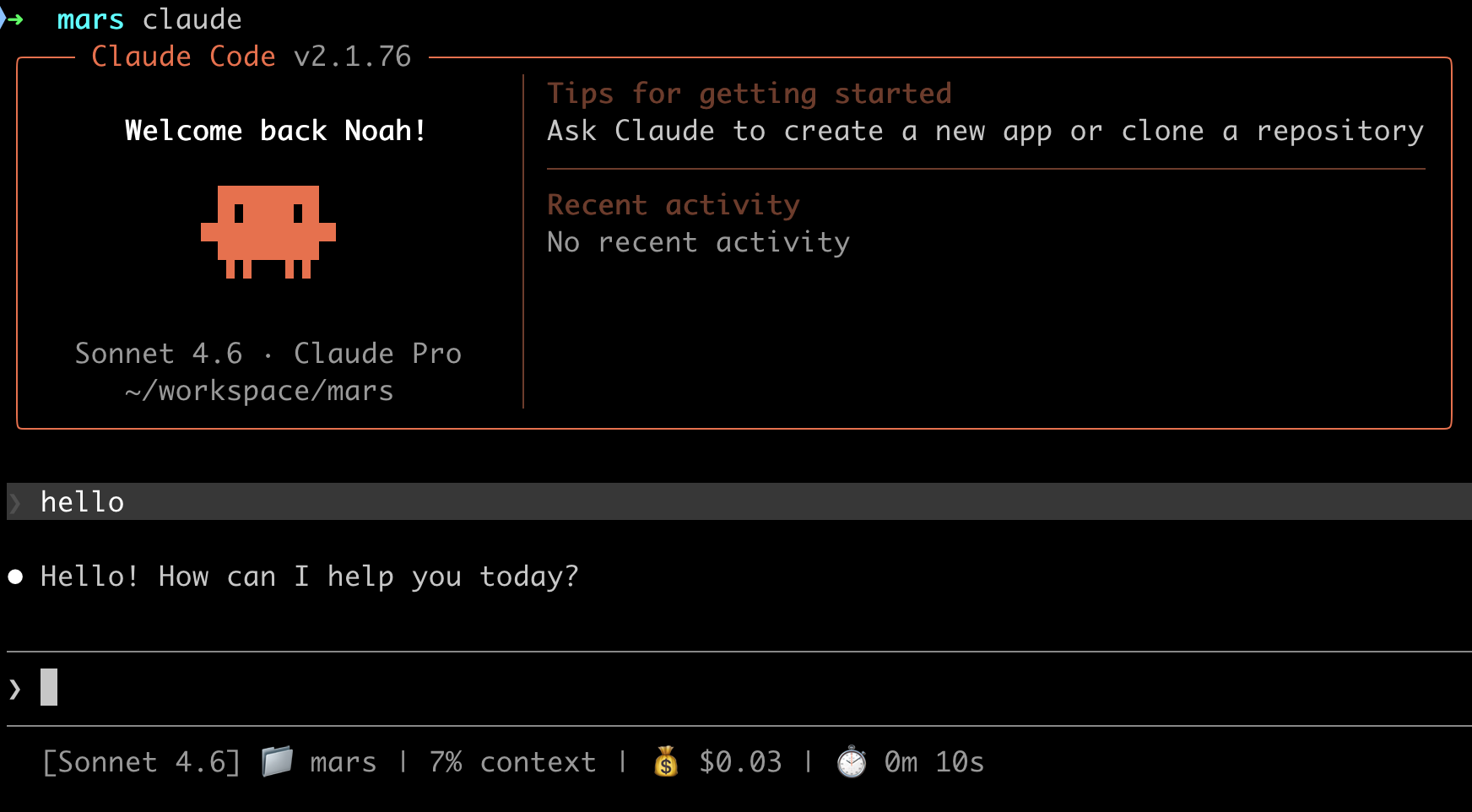
可以看到最后一行我添加了一些个性化的信息在上面。
这个实现起来也非常简单,你可以直接把我这个图片扔给 Claude Code,让它帮你实现。
第一步,打开 ~/.claude/settings.json 文件,在里面添加一个 statusLine 的描述:
{
"alwaysThinkingEnabled": true,
"statusLine": {
"type": "command",
"command": "bash ~/.claude/statusline-command.sh"
}
...
}这里面需要一个 statusline-command.sh,我的内容如下:
#!/bin/bash
# Read JSON data that Claude Code sends to stdin
input=$(cat)
# Extract fields using jq
MODEL=$(echo "$input" | jq -r '.model.display_name')
DIR=$(echo "$input" | jq -r '.workspace.current_dir')
# The "// 0" provides a fallback if the field is null
PCT=$(echo "$input" | jq -r '.context_window.used_percentage // 0' | cut -d. -f1)
COST=$(echo "$input" | jq -r '.cost.total_cost_usd // 0')
DURATION_MS=$(echo "$input" | jq -r '.cost.total_duration_ms // 0')
COST_FMT=$(printf '$%.2f' "$COST")
DURATION_SEC=$((DURATION_MS / 1000))
MINS=$((DURATION_SEC / 60))
SECS=$((DURATION_SEC % 60))
echo "[$MODEL] 📁 ${DIR##*/} | ${PCT}% context | 💰 $COST_FMT | ⏱️ ${MINS}m ${SECS}s"当然你也可以添加一些其他的信息,可以参考官方文档看有哪些变量可以用。
MCP
add on 2026-03-17
在 Skills 出来之前,MCP 承担了非常多的职责,大家快把它吹爆了,它最大的问题就在于它会消耗掉大量的 token。
即使我们没有用到某个 mcp,但是我们的 context 中依然包含了它的工具定义,比如大家通常会使用 github 的 mcp,因为可以用它来创建 PR,做 code review 等,但你可能不知道的是,github 的 mcp 需要消耗几万个 token。
对于 Github 这个例子,其实很容易解决,使用本地安装的 gh 就可以了,让 Claude Code 调用 gh 工具来替代 mcp。
自从大家开始转向 Skills 以后,MCP 就慢慢退化成访问企业内网资源的工具,比如访问内网的 confluence、jira 等。
MCP 也可以分项目级别和用户级别,用户级别的配置在 ~/.claude.json 文件中,至于怎么配置,就不展示介绍了,非常简单。
小结
现在底层大模型的能力很强,尤其是头部的几家。但是大模型的输出质量,很大程度上取决于喂给它的上下文,这里面包含我们自定义的,也包含工具帮我们封装的。
同样底层使用 Claude Sonnet 4.5 模型,你在 Cursor 里面用,和在 Claude Code 里面用,差距其实蛮明显的,这就是工具在上下文上做了很多优化工作。
当然,本文没有介绍 Hooks,MCP 等内容,在很多的团队里面,这些也是非常实用的。
欢迎大家在评论区讨论更多内容。
(全文完)
0 条评论