本文介绍阿里开源的 Sentinel 源码,GitHub: alibaba/Sentinel,基于当前(2019-12)最新的 release 版本 1.7.0。
总体来说,Sentinel 的源码比较简单,复杂的部分在于它的模型对于初学者来说不好理解。
虽然本文不是很长,最后两节还和主流程无关,但是,本文对于源码分析已经非常细致了。
阅读建议:在阅读本文前,你应该至少了解过 Sentinel 是什么,如果使用过 Sentinel 或已经阅读过部分源码那就更好了。
另外,本文不涉及到集群流控。由于很多读者也没使用过 Hystrix,所以本文也不做任何对比。
更新 2019-12-11:更新了滑动窗口秒级数据统计 OccupiableBucketLeapArray 的分析。
简介
Sentinel 的定位是流量控制、熔断降级,你应该把它理解为一个第三方 Jar 包。
这个 Jar 包会进行流量统计,执行流量控制规则。而统计数据的展示和规则的设置在 sentinel-dashboard 项目中,这是一个 Spring MVC 应用,有后台管理界面,我们通过这个管理后台和各个应用进行交互。
当然,你不一定需要 dashboard,很长一段时间,我仅仅使用 sentinel-core,它会将统计信息写入到指定的日志文件中,我通过该文件内容来了解每个接口的流量情况。当然,这种情况下,我只是使用到了 Sentinel 的流量监控功能而已。

从左侧我们可以看到这个 dashboard 可以管理很多应用,而对于每个应用,我们还可以有很多机器实例(见机器列表)。我们在这个后台,可以非常直观地了解到每个接口的 QPS 数据,我们可以对每个接口设置流量控制规则、降级规则等。
这个 dashboard 应用默认是不持久化数据的,它的所有数据都是在内存中的,所以 dashboard 重启意味着所有的数据都会丢失。你应该按照自己的需要来定制化 dashboard,如至少你应该要持久化规则设置,QPS 数据非常适合存放在时序数据库中,当然如果你的数据量不大,存 MySQL 也问题不大,定期清理一下过期数据即可,因为大部分人应该不会关心一个月以前的 QPS 数据。
sentinel-dashboard 并没有定位为一个功能强大的管理后台,一般来说,我们需要基于它来进行二次开发,甚至于你也可以不使用这个 Java 项目,自己使用其他的语言来实现。在最后一小节,我介绍了业务应用是怎么和 dashboard 应用交互的。
Sentinel 的数据统计
在正式开始介绍 Sentinel 的流程源码之前,我想先和大家介绍一下 Sentinel 的数据统计模块的内容,这样读者在后面看到相应的内容的时候心里有一些底。这节内容还是比较简单的,当然,如果你希望立马进入 Sentinel 的主流程,可以先跳过这一节。
Sentinel 的定位是流量控制,它有两个维度的控制,一个是控制并发线程数,另一个是控制 QPS,它们都是针对某个具体的接口来设置的,其实说资源比较准确,Sentinel 把控制的粒度定义为 Resource。
既然要做控制,那么首先,Sentinel 就要先做统计,它要知道当前接口的 QPS 和并发是多少,进而判断一个新的请求能不能让它通过。
这里我们先抛开 Sentinel 的各种概念,直接先看下数据统计的代码。数据统计的代码在 StatisticNode 中,对于 QPS 数据,它使用了滑动窗口的设计:
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
private transient Metric rollingCounterInMinute = new ArrayMetric(60, 60 * 1000, false);
private AtomicInteger curThreadNum = new AtomicInteger(0);先看最后的属性 curThreadNum,它使用 AtomicInteger 来统计并发量,就是原子加、原子减的操作,非常简单,这里不浪费篇幅了,下面仅介绍 QPS 的统计。
从上面的代码也可以知道,Sentinel 统计了 秒 和 分 两个维度的数据,下面我们简单说说实现类 ArrayMetric 的源码设计。
public class ArrayMetric implements Metric {
private final LeapArray<MetricBucket> data;
public ArrayMetric(int sampleCount, int intervalInMs) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
}
public ArrayMetric(int sampleCount, int intervalInMs, boolean enableOccupy) {
if (enableOccupy) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
} else {
this.data = new BucketLeapArray(sampleCount, intervalInMs);
}
}
......
}ArrayMetric 的内部是一个 LeapArray,我们以分钟维度统计的使用来说,它使用子类 BucketLeapArray 实现。
这里先介绍较为简单的 BucketLeapArray 的实现,然后在最后一节会介绍 OccupiableBucketLeapArray。
public abstract class LeapArray<T> {
protected int windowLengthInMs;
protected int sampleCount;
protected int intervalInMs;
protected final AtomicReferenceArray<WindowWrap<T>> array;
// 对于分钟维度的设置,sampleCount 为 60,intervalInMs 为 60 * 1000
public LeapArray(int sampleCount, int intervalInMs) {
// 单个窗口长度,这里是 1000ms
this.windowLengthInMs = intervalInMs / sampleCount;
// 一轮总时长 60,000 ms
this.intervalInMs = intervalInMs;
// 60 个窗口
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}
// ......
}它的内部核心是一个数组 array,它的长度为 60,也就是有 60 个窗口,每个窗口长度为 1 秒,刚好一分钟走完一轮。然后下一轮开启“覆盖”操作。

每个窗口是一个 WindowWrap 类实例。
-
添加数据的时候,先判断当前走到哪个窗口了(当前时间(s) % 60 即可),然后需要判断这个窗口是否是过期数据,如果是过期数据(窗口代表的时间距离当前已经超过 1 分钟),需要先重置这个窗口实例的数据。
-
统计数据同理,如统计过去一分钟的 QPS 数据,就是将每个窗口的值相加,当中需要判断窗口数据是否是过期数据,即判断窗口的 WindowWrap 实例是否是一分钟内的数据。
核心逻辑都封装在了 currentWindow(long timeMillis) 和 values(long timeMillis)方法中。
添加数据的时候,我们要先获取操作的目标窗口,也就是 currentWindow 这个方法,Sentinel 在这里处理初始化和过期重置的情况:
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 获取窗口下标
int idx = calculateTimeIdx(timeMillis);
// 计算该窗口的理论开始时间
long windowStart = calculateWindowStart(timeMillis);
// 嵌套在一个循环中,因为有并发的情况
while (true) {
WindowWrap<T> old = array.get(idx);
if (old == null) {
// 窗口未实例化的情况,使用一个 CAS 来设置该窗口实例
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
// 存在竞争
Thread.yield();
}
} else if (windowStart == old.windowStart()) {
// 当前数组中的窗口没有过期
return old;
} else if (windowStart > old.windowStart()) {
// 该窗口已过期,重置窗口的值。使用一个锁来控制并发。
if (updateLock.tryLock()) {
try {
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// 正常情况都不会走到这个分支,异常情况其实就是时钟回拨,这里返回一个 WindowWrap 是容错
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}获取数据,使用的是 values 方法,这个方法返回“有效的”窗口中的数据:
public List<T> values(long timeMillis) {
if (timeMillis < 0) {
return new ArrayList<T>();
}
int size = array.length();
List<T> result = new ArrayList<T>(size);
for (int i = 0; i < size; i++) {
WindowWrap<T> windowWrap = array.get(i);
// 过滤掉过期数据
if (windowWrap == null || isWindowDeprecated(timeMillis, windowWrap)) {
continue;
}
result.add(windowWrap.value());
}
return result;
}
// 判断当前窗口的数据是否是 60 秒内的
public boolean isWindowDeprecated(long time, WindowWrap<T> windowWrap) {
return time - windowWrap.windowStart() > intervalInMs;
}这个 values 方法很简单,就是过滤掉那些过期数据就可以了。
到这里,我们就说完了 分 维度数据统计的问题。至于秒维度的数据统计,有些不一样,稍微复杂一些,我在后面单独起了一节。跳过这部分内容对阅读 Sentinel 源码没有影响。
Sentinel 源码分析
下面,我们正式开始 Sentinel 的源码介绍。
官方文档中,它的最简单的使用是下面这样的,这里用了 try-with-resource 的写法:
try (Entry entry = SphU.entry("HelloWorld")) {
// Your business logic here.
System.out.println("hello world");
} catch (BlockException e) {
// Handle rejected request.
e.printStackTrace();
}这个例子对于理解源码其实不是很好,我们来写一个复杂一些的例子,这样对理解源码有很大的帮助:
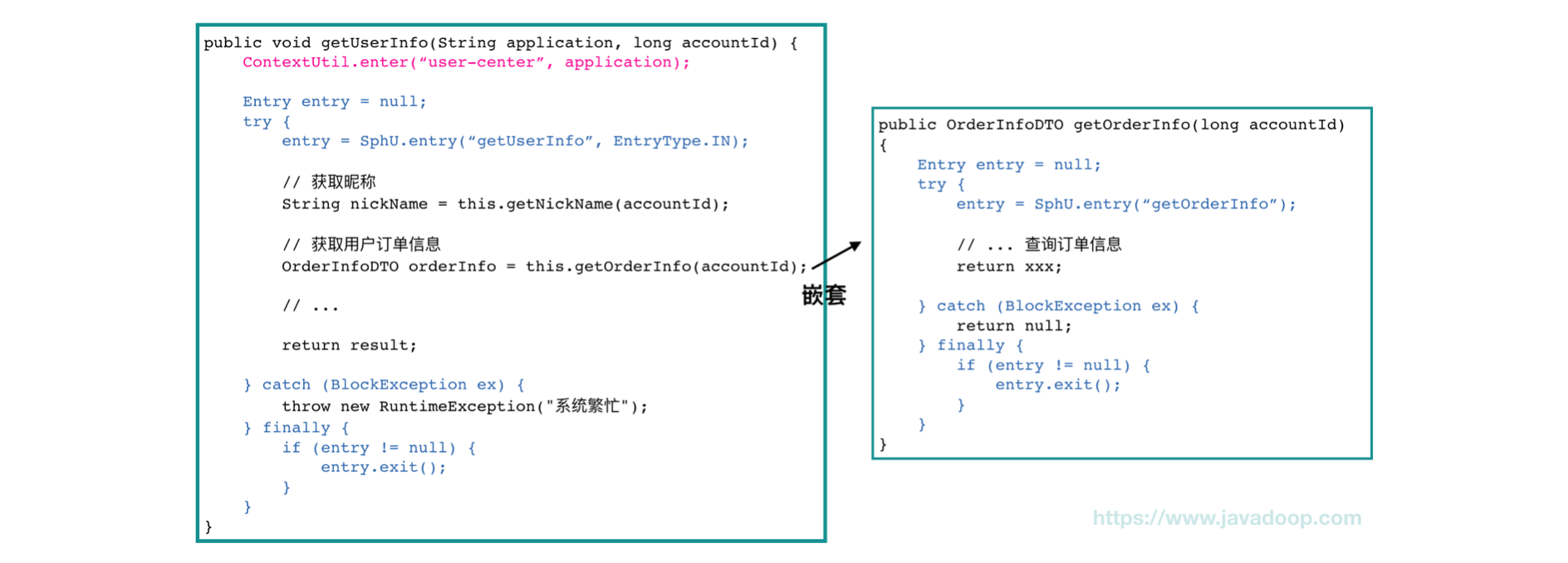
1、红色部分,Context 代表一个调用链的入口,Context 实例设置在 ThreadLocal 中,所以它是跟着线程走的,如果要切换线程,需要手动切换。ContextUtil#enter 有两个参数:
第一个参数是 context name,它代表调用链的入口,作用是为了区分不同的调用链路,个人感觉没什么用,默认是 Constants.CONTEXT_DEFAULT_NAME 的常量值 "sentinel_default_context";
第二个参数代表调用方标识 origin,目前它有两个作用,一是用于黑白名单的授权控制,二是可以用来统计诸如从应用 application-a 发起的对当前应用 interfaceXxx() 接口的调用,目前这个数据会被统计,但是 dashboard 中并不展示。
2、进入 BlockException 异常分支,代表该次请求被流量控制规则限制了,我们一般会让代码走入到熔断降级的逻辑里面。当然,BlockException 其实有好多个子类,如 DegradeException、FlowException 等,我们也可以 catch 具体的子类来进行处理。
3、Entry 是我们的重点,对于 SphU#entry 方法:
第一个参数标识资源,通常就是我们的接口标识,对于数据统计、规则控制等,我们一般都是在这个粒度上进行的,根据这个字符串来唯一标识,它会被包装成 ResourceWrapper 实例,大家要先看下它的 hashCode 和 equals 方法;
第二个参数标识资源的类型,我们左边的代码使用了 EntryType.IN 代表这个是入口流量,比如我们的接口对外提供服务,那么我们通常就是控制入口流量;EntryType.OUT 代表出口流量,比如上面的 getOrderInfo 方法(没写默认就是 OUT),它的业务需要调用订单服务,像这种情况,压力其实都在订单服务中,那么我们就指定它为出口流量。这个流量类型有什么用呢?答案在 SystemSlot 类中,它用于实现自适应限流,根据系统健康状态来判断是否要限流,如果是 OUT 类型,由于压力在外部系统中,所以就不需要执行这个规则。
4、上面的代码,我们在 getOrderInfo 中嵌套使用了 Entry,也是为了我们后面的源码分析需要。如果我们在一个方法中写的话,要注意内层的 Entry 先 exit,才能做外层的 exit,否则会抛出异常。源码角度来看,是在 Context 实例中,保存了当前的 Entry 实例。
5、实际开发过程中,我们当然不会每个接口都像上面的代码这么写,Sentinel 提供了很多的扩展和适配器,这里只是为了源码分析的需要。
Sentinel 提供了很多的 adapter 用于诸如 dubbo、grpc、网关等环境,它们其实都是封装了上述的代码。你只要认真看完本文,那些包装都很容易看懂。
这里我们介绍了 Sentinel 的接口使用,不过它的类名字我现在都没懂是什么意思,SphU、CtSph、CtEntry 这些名字有什么特殊含义,有知道的读者请不吝赐教。
下面,我们按照上面的代码,开始源码分析。这里我不会像之前分析 Spring IOC 和 Netty 源码一样,一行一行代码说,所以大家一定要打开源码配合着看。
ContextUtil#enter
我们先看 Context#enter 方法,这行代码我们是可以不写的,通常情况下,我们都不会显示设置 context。
ContextUtil.enter("user-center", "app-A"); 下面我们就会看到,如果我们不显式调用这个方法,那么会进入到默认的 context 中。
进入到 ContextUtil 类,大家可能会漏看它的 static 代码块,这里会添加一个默认的 EntranceNode 实例。
然后上面的这个方法会走到 ContextUtil#trueEnter 中,这里会添加名为 "user-center" 的 EntranceNode 节点。根据源码,我们可以得出下面这棵树:
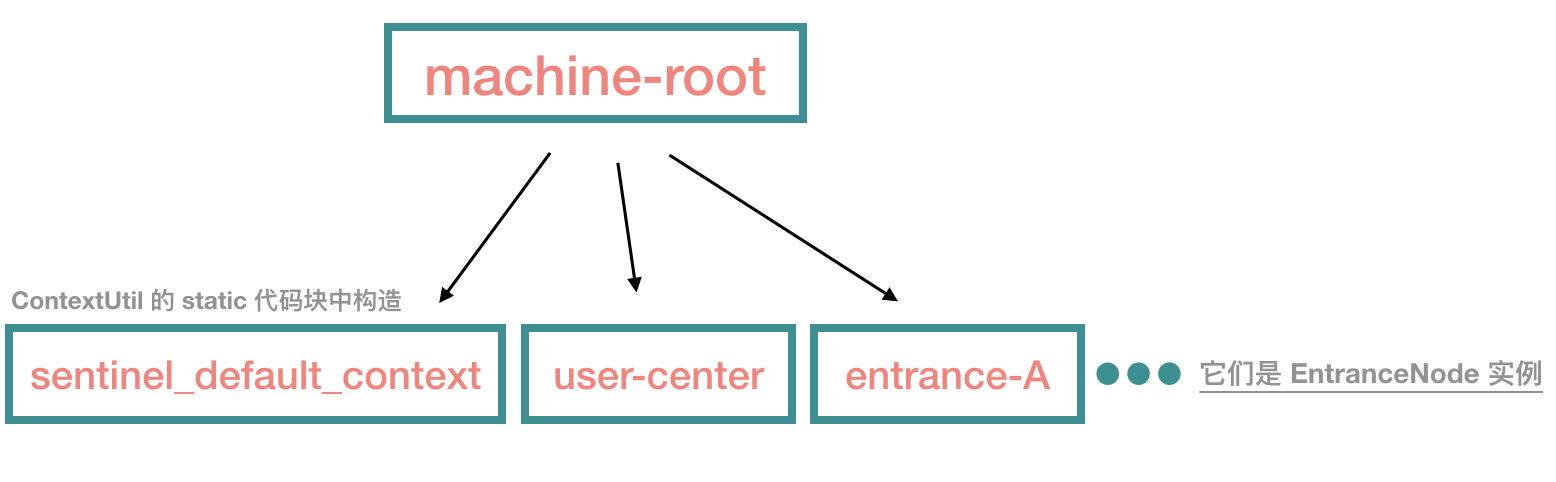
这里的源码非常简单,如果我们从来不显式调用 ContextUtil#enter 方法的话,那 root 就只有一个 default 子节点 sentinel_default_context。
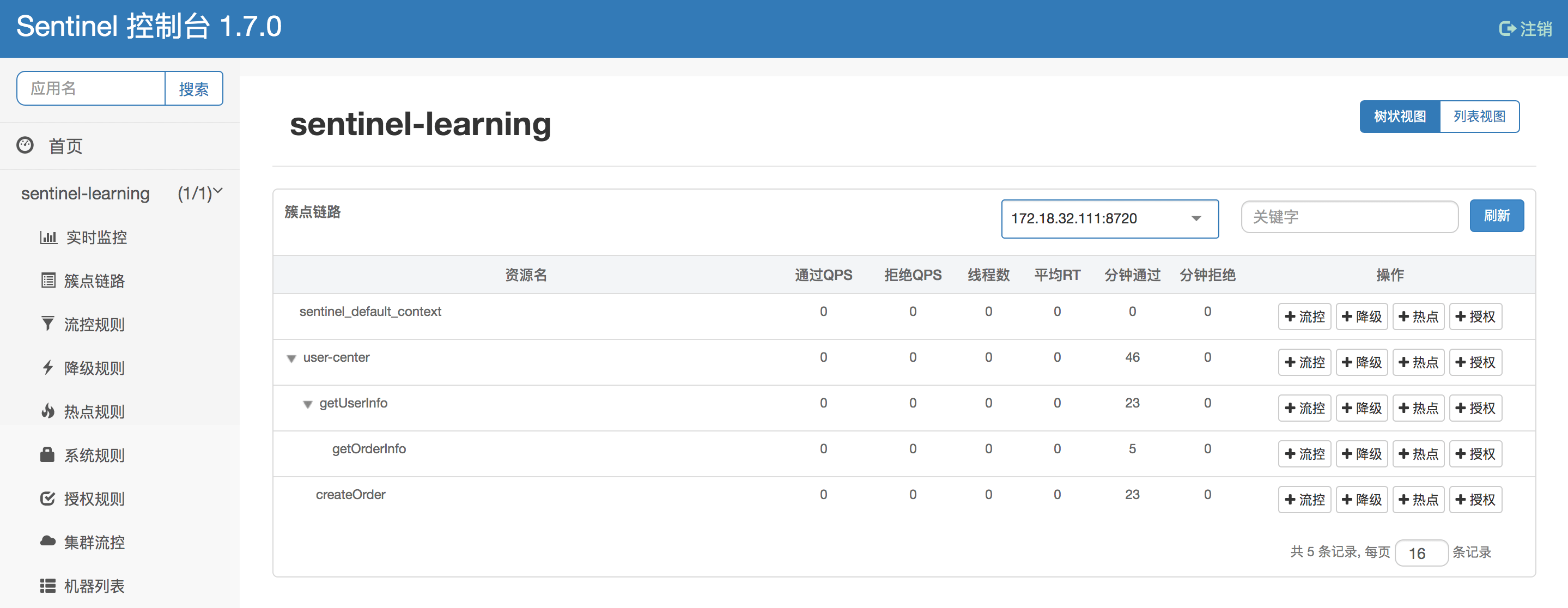
context 很好理解,它代表线程执行的上下文,在各种开源框架中都有类似的语义,在 Sentinel 中,我们可以看到,对于一个新的 context name,Sentinel 会往树中添加一个 EntranceNode 实例。它的作用是为了区分调用链路,标识调用入口。在 sentinel-dashboard 中,我们可以很直观地看出调用链路:
SphU#entry
接下来,我们看 SphU#entry。自己跟进去,我们会来到 CtSph#entryWithPriority 方法,这个方法是 Sentinel 的骨架,非常重要。
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 从 ThreadLocal 中获取 Context 实例
Context context = ContextUtil.getContext();
// 如果是 NullContext,那么说明 context name 超过了 2000 个,参见 ContextUtil#trueEnter
// 这个时候,Sentinel 不再接受处理新的 context 配置,也就是不做这些新的接口的统计、限流熔断等
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
// 我们前面说了,如果我们不显式调用 ContextUtil#enter,这里会进入到默认的 context 中
if (context == null) {
context = MyContextUtil.myEnter(Constants.CONTEXT_DEFAULT_NAME, "", resourceWrapper.getType());
}
// Sentinel 的全局开关,Sentinel 提供了接口让用户可以在 dashboard 开启/关闭
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
// 设计模式中的责任链模式。
// 下面这行代码用于构建一个责任链,入参是 resource,前面我们说过资源的唯一标识是 resource name
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
// 根据 lookProcessChain 方法,我们知道,当 resource 超过 Constants.MAX_SLOT_CHAIN_SIZE,
// 也就是 6000 的时候,Sentinel 开始不处理新的请求,这么做主要是为了 Sentinel 的性能考虑
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
// 执行这个责任链。如果抛出 BlockException,说明链上的某一环拒绝了该请求,
// 把这个异常往上层业务层抛,业务层处理 BlockException 应该进入到熔断降级逻辑中
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}前面的都比较简单,这里说一说 lookProcessChain(resourceWrapper) 这个方法。Sentinel 的处理核心都在这个责任链中,链中每一个节点是一个 Slot 实例,这个链通过 BlockException 异常来告知调用入口最终的执行情况。
大家自己点进去源码,这个责任链由 SlotChainProvider#newSlotChain 生产,Sentinel 提供了 SPI 端点,让我们可以自己定制 Builder,如添加一个 Slot 进去。由于 SlotChainBuilder 接口设计的问题,我们只能全局所有的 resource 使用相同的责任链配置。
public class DefaultSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new LogSlot());
chain.addLast(new StatisticSlot());
chain.addLast(new AuthoritySlot());
chain.addLast(new SystemSlot());
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
return chain;
}
}接下来,我们就按照默认的 DefaultSlotChainBuilder 生成的责任链往下看源码。
这里要强调一点,对于相同的 resource,使用同一个责任链实例,不同的 resource,使用不同的责任链实例。
另外,对于 resource 实例,我们前面也说了,它根据 resource name 来判断,和线程没有关系。
NodeSelectorSlot

首先,链中第一个处理节点是 NodeSelectorSlot。
// key 是 context name, value 是 DefaultNode 实例
private volatile Map<String, DefaultNode> map = new HashMap<String, DefaultNode>(10);
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
throws Throwable {
DefaultNode node = map.get(context.getName());
if (node == null) {
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
node = new DefaultNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
// Build invocation tree
((DefaultNode) context.getLastNode()).addChild(node);
}
}
}
context.setCurNode(node);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}我们前面说了,责任链实例和 resource name 相关,和线程无关,所以当处理同一个 resource 的时候,会进入到同一个 NodeSelectorSlot 实例中。
所以这块代码主要就是要处理:不同的 context name,同一个 resource name 的情况。
如下面两段代码,它们都是处理同一个 resource("getUserInfo" 这个 resource),但是它们的入口 context 不一致。

然后我们再结合前面的那棵树,我们可以得出下面这棵树,看深色的部分:
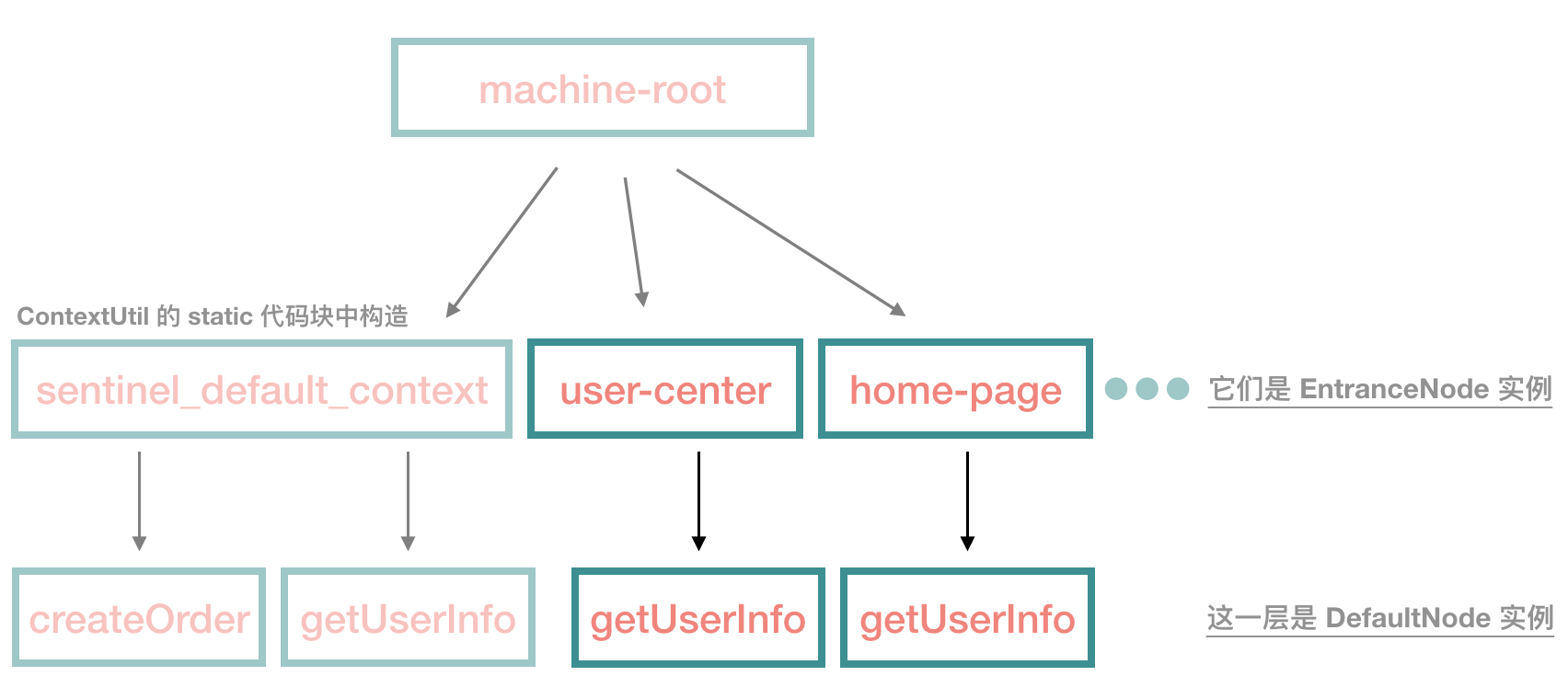
NodeSelectorSlot 还是比较简单的,只要读者搞清楚 NodeSelectorSlot 实例是跟着 resource 一一对应的就很清楚了。
ClusterBuilderSlot

接下来,我们来到了 ClusterBuilderSlot 这一环,这一环的主要作用是构建 ClusterNode。
这里不贴源码,根据上面的树,然后在经过该类的处理以后,我们可以得出下面这棵树:
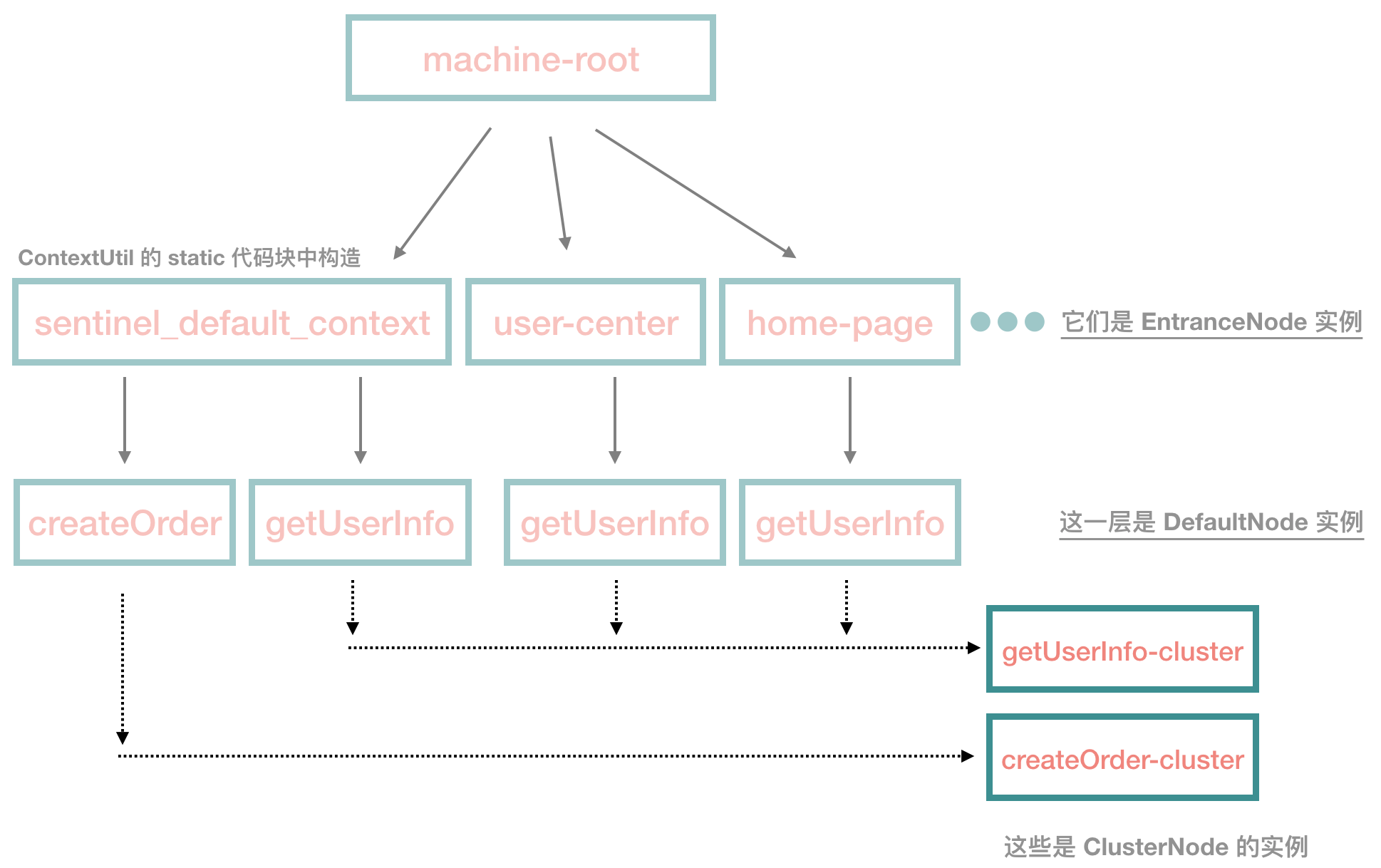
看上图中深色部分,对于每一个 resource,这里会对应一个 ClusterNode 实例,如果不存在,就创建一个实例。
这个 ClusterNode 非常有用,因为我们就是使用它来做数据统计的。比如 getUserInfo 这个接口,由于从不同的 context name 中开启调用链,它有多个 DefaultNode 实例,但是只有一个 ClusterNode,通过这个实例,我们可以知道这个接口现在的 QPS 是多少。
另外,这个类还处理了 origin 不是默认值的情况:
再说一次,origin 代表调用方标识,如 application-a, application-b 等。
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}我们可以看到,当设置了 origin 的时候,会额外生成一个 StatisticsNode 实例,挂在 ClusterNode 上。
我们把前面的代码改改,看红色部分:

我们的 getUserInfo 接收到了来自 application-a 和 application-b 两个应用的请求,那么树会变成下面这样:
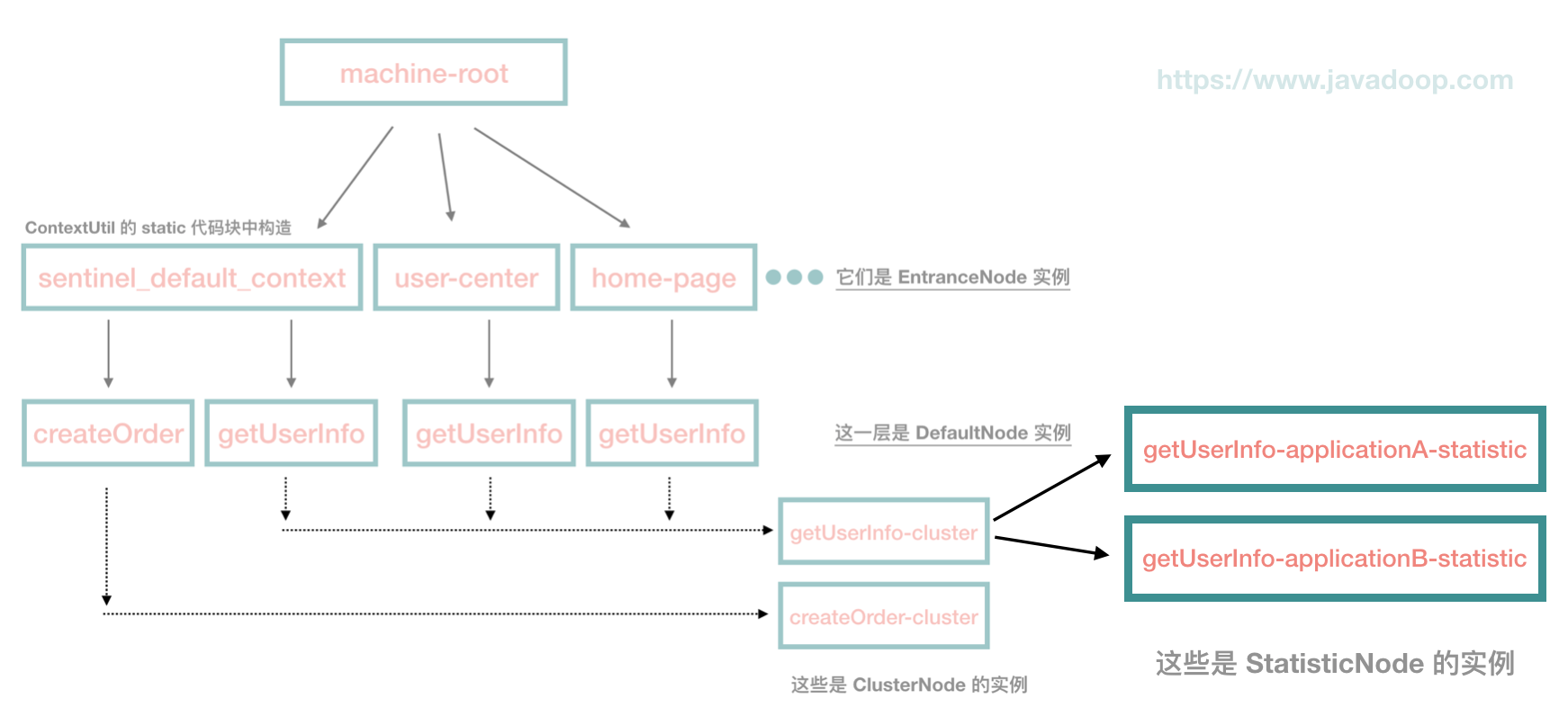
它的作用是用来统计从 application-a 过来的访问 getUserInfo 这个接口的信息。目前这个信息在 dashboard 中是不展示的,毕竟也没什么用。
LogSlot

这个类比较简单,我们看到它直接 fire 出去了,也就是说,先处理责任链上后面的那些节点,如果它们抛出了 BlockException,那么这里才做处理。
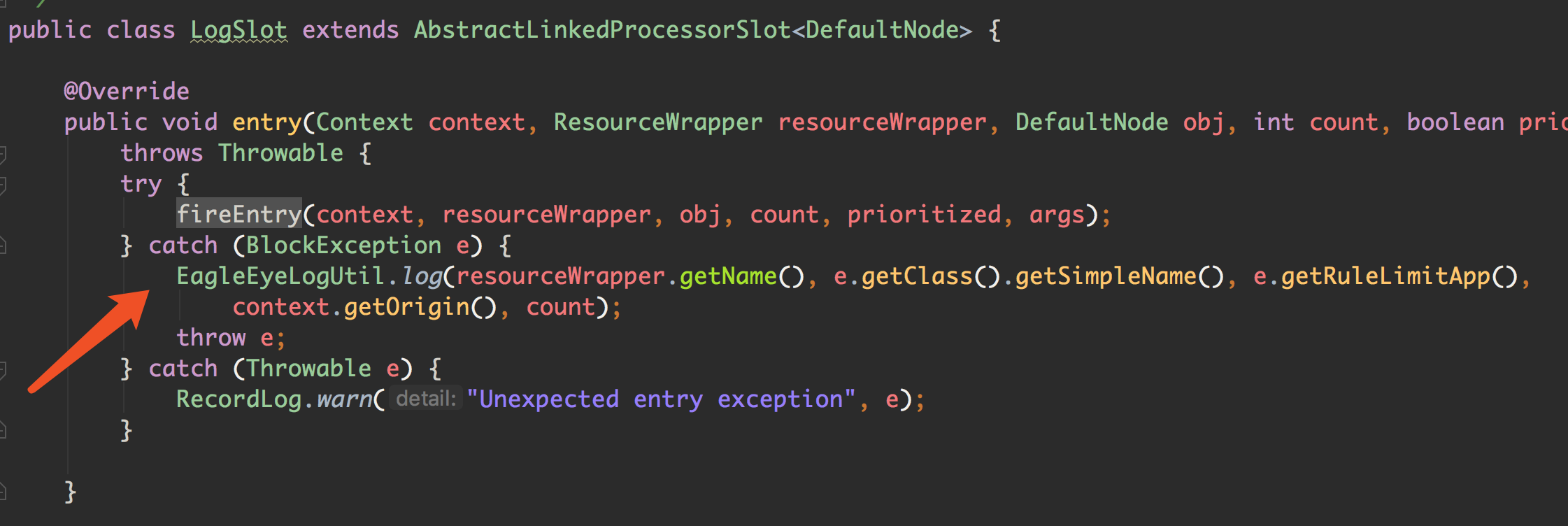
这里调用了 EagleEyeLogUtil#log 方法,它其实就是,将被设置的规则 block 的信息记录到日志文件 sentinel-block.log 中。也就是记录哪些接口被规则挡住了。
StatisticSlot

这个 slot 非常重要,它负责进行数据统计。
它也是先 fire 出去,等后面的节点处理完毕以后,它再进行统计数据。之所以这么设计,是因为后面的节点是做控制的,执行的时候可能是正常通过的,也可能是抛出 BlockException 异常的。
源码非常简单,对于 QPS 统计,使用前面介绍的滑动窗口,而对于线程并发的统计,它使用了 LongAdder。
大家一定要看一遍这个类的源码,这里没有什么特别的内容需要强调,所以我就不展开说了。
接下来,我们后面要介绍的几个 Slot,需要通过 dashboard 进行开启,因为需要配置规则。
当然,你也可以硬编码规则到代码中。但是要调整数值就比较麻烦,每次都要改代码。
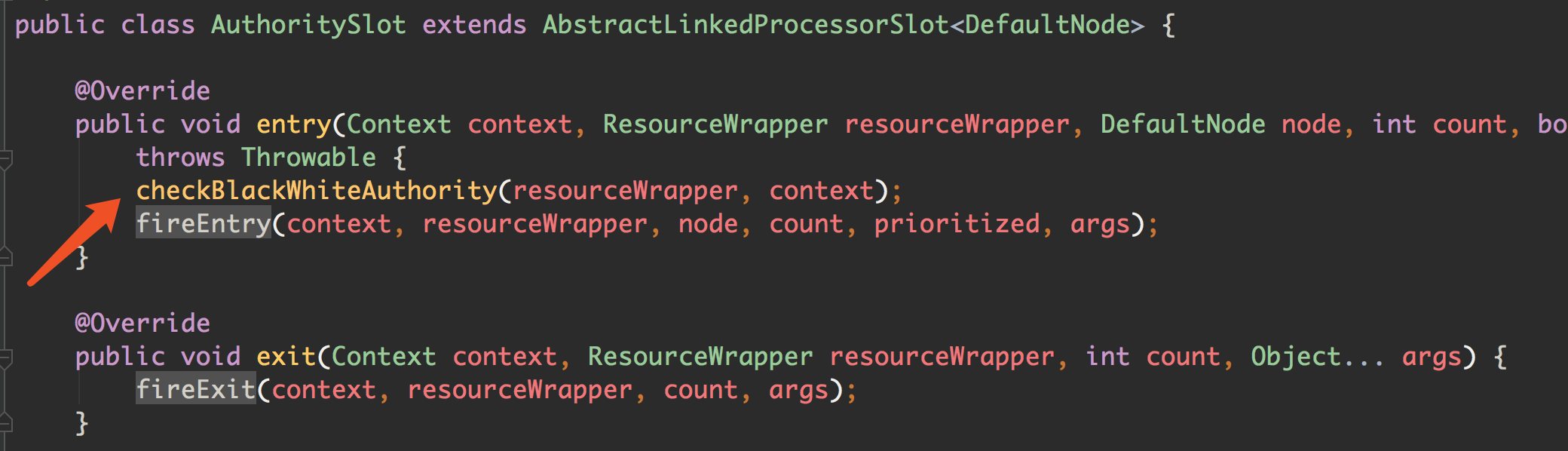
AuthoritySlot

这个类非常简单,做权限控制,根据 origin 做黑白名单的控制:
在 dashboard 中,是这么配置的:
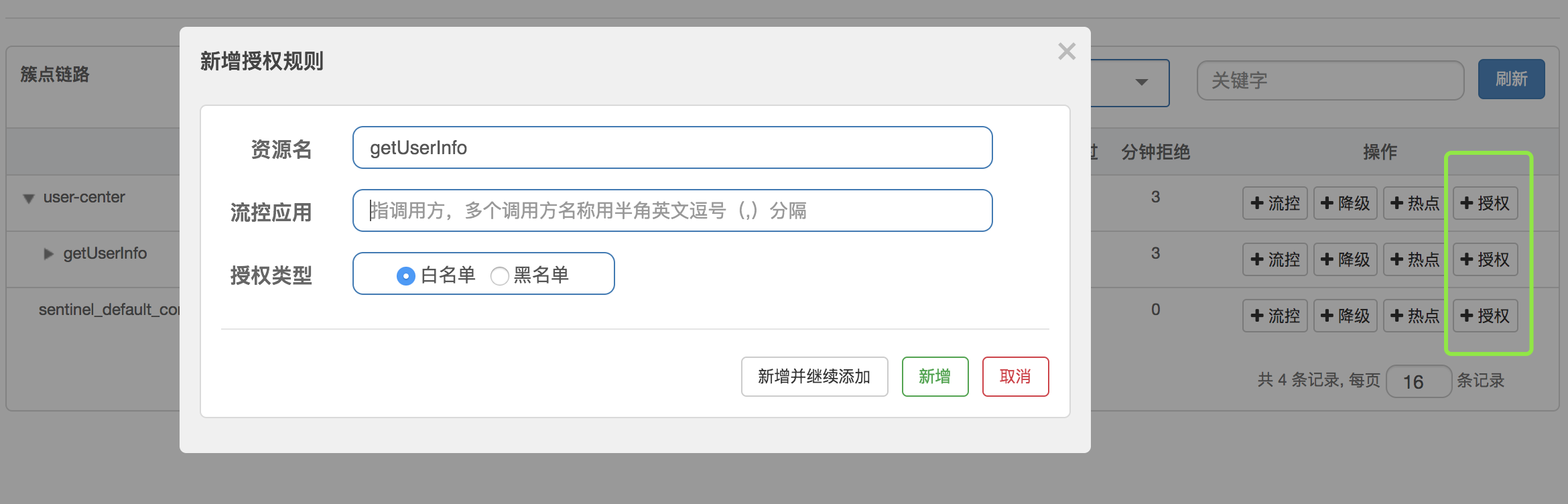
这里的调用方就是我们前面介绍的 origin。
SystemSlot

这个是 Sentinel 中比较重要的一个东西了,用来实现自适应限流。
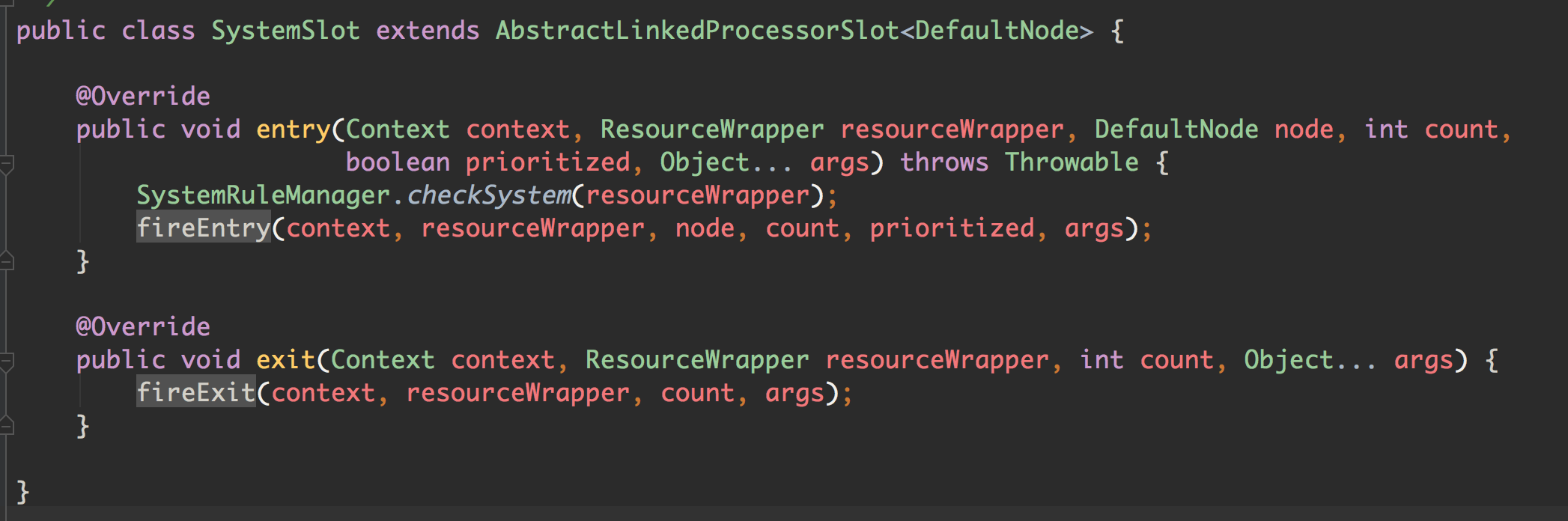
规则校验都在 SystemRuleManager#checkSystem 中:
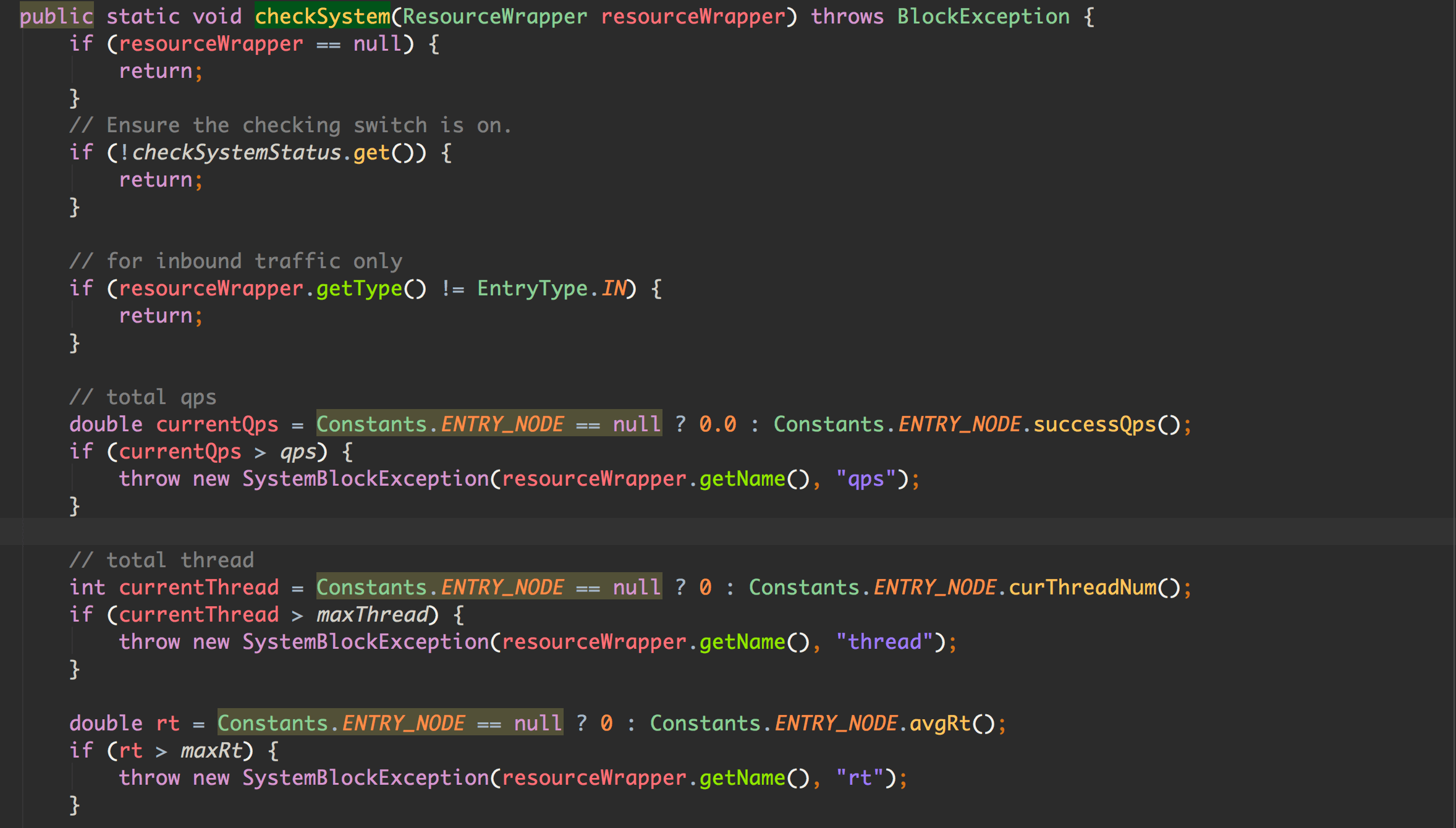
我们先说说上面的代码中的 RT、线程数、入口 QPS 这三项系统保护规则。dashboard 配置界面:
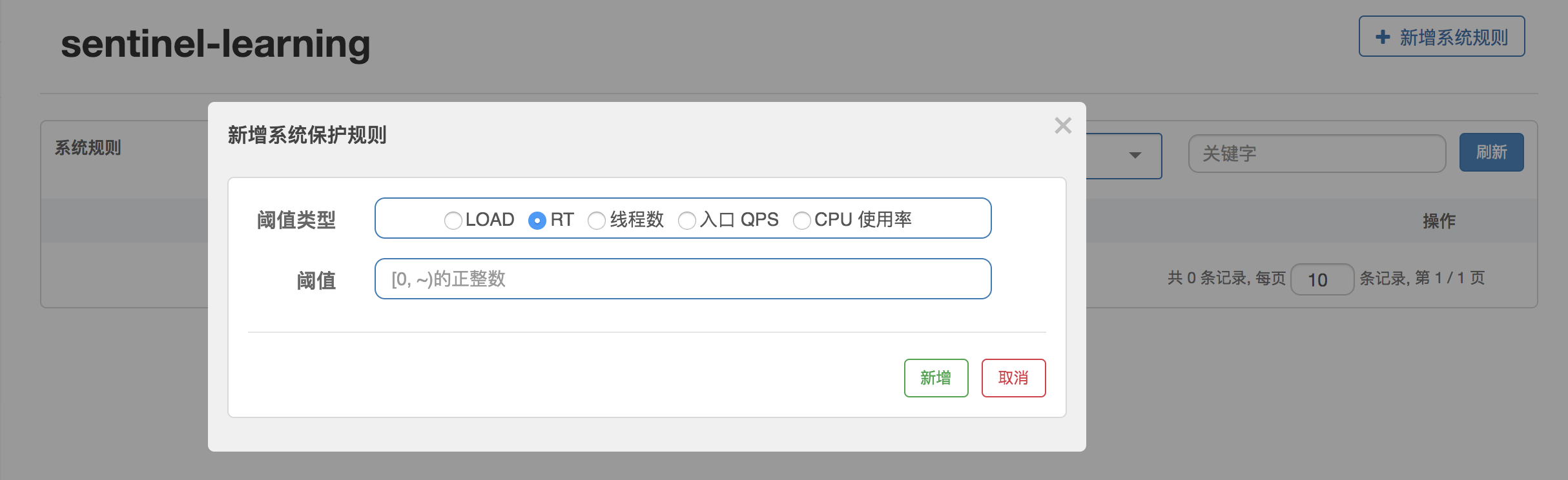
在前面介绍的 StatisticSlot 类中,有下面一段代码:
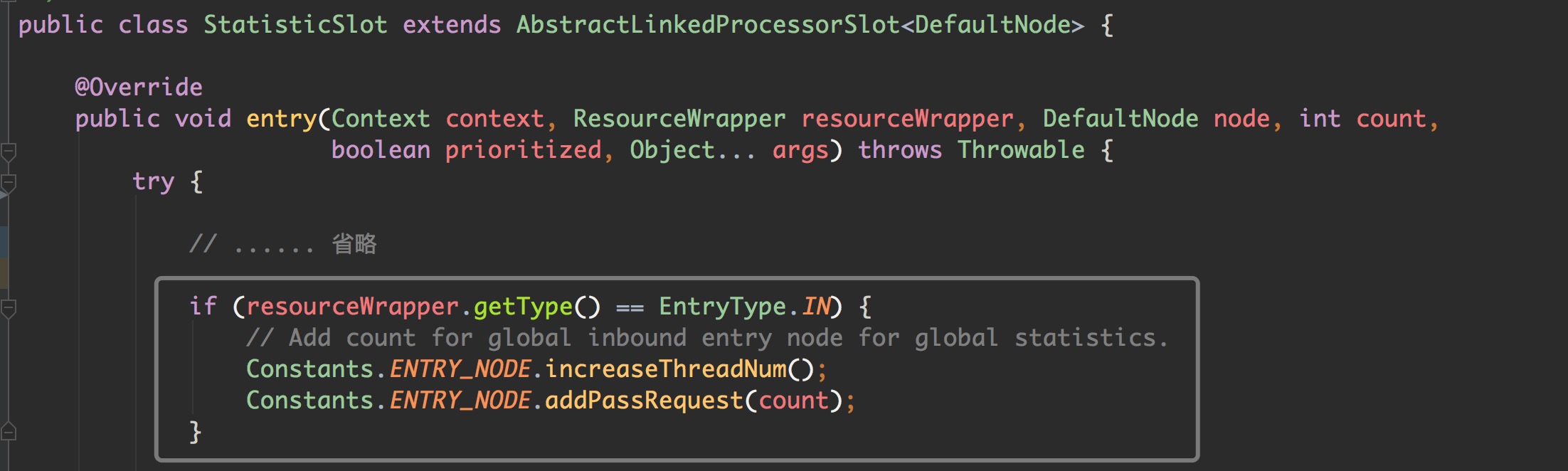
Sentinel 针对所有的入口流量,使用了一个全局的 ENTRY_NODE 进行统计,所以我们也要知道,系统保护规则是全局的,和具体的某个资源没有关系。
由于系统的平均 RT、当前线程数、QPS 都可以从 ENTRY_NODE 中获得,所以限制代码非常简单,比较一下大小就可以了。如果超过阈值,抛出 SystemBlockException。
ENTRY_NODE 是 ClusterNode 类型的,而 ClusterNode 对于 rt、qps 都是统计的秒维度的数据。
当然,对于 SystemSlot 类来说,最重要的其实并不是上面的这些,因为在实际使用过程中,对于 RT、线程数、QPS 每一项,我们其实都很难设置一个确定的阈值。
我们往下看它的对于系统负载和 CPU 资源的保护:
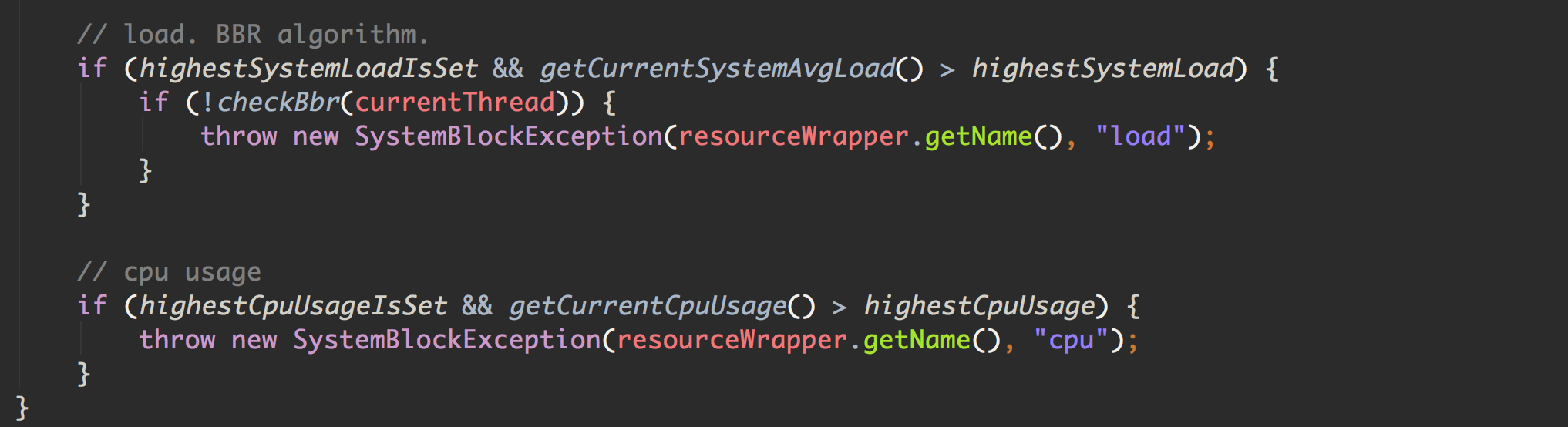
我们可以看到,Sentinel 通过调用 MBean 中的方法获取当前的系统负载和 CPU 使用率,Sentinel 起了一个后台线程,每秒查询一次。
OperatingSystemMXBean osBean = ManagementFactory.getPlatformMXBean(OperatingSystemMXBean.class);
currentLoad = osBean.getSystemLoadAverage();
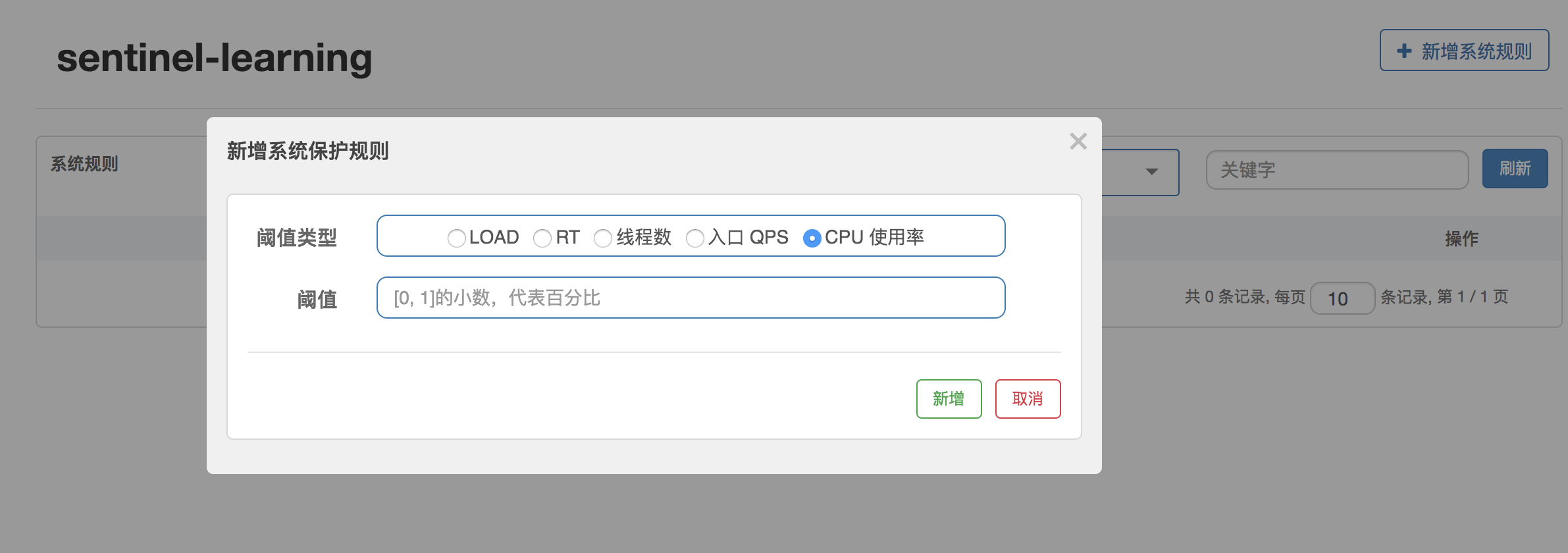
currentCpuUsage = osBean.getSystemCpuLoad();下图展示 dashboard 中对于 CPU 使用率的规则配置:
FlowSlot

Flow Control 是 Sentinel 的核心, 因为 Sentinel 本身定位就是一个流控工具,所以 FlowSlot 非常重要。
对于读者来说,最大的挑战应该也是这部分代码,因为前面的代码,只要读者理得清楚里面各个类的关系,就不难。而这部分代码由于涉及到限流算法,会稍微复杂一点点。
我之前写过一篇 RateLimiter 源码分析(Guava 和 Sentinel 实现) 文章,里面介绍了 Sentinel 使用的流控算法,所以我这里就不准备再花篇幅介绍这部分内容了。感兴趣的读者请阅读那篇文章即可。
DegradeSlot

恭喜大家,终于到最后一个 slot 了。
它有三个策略,我们首先说说根据 RT 降级:
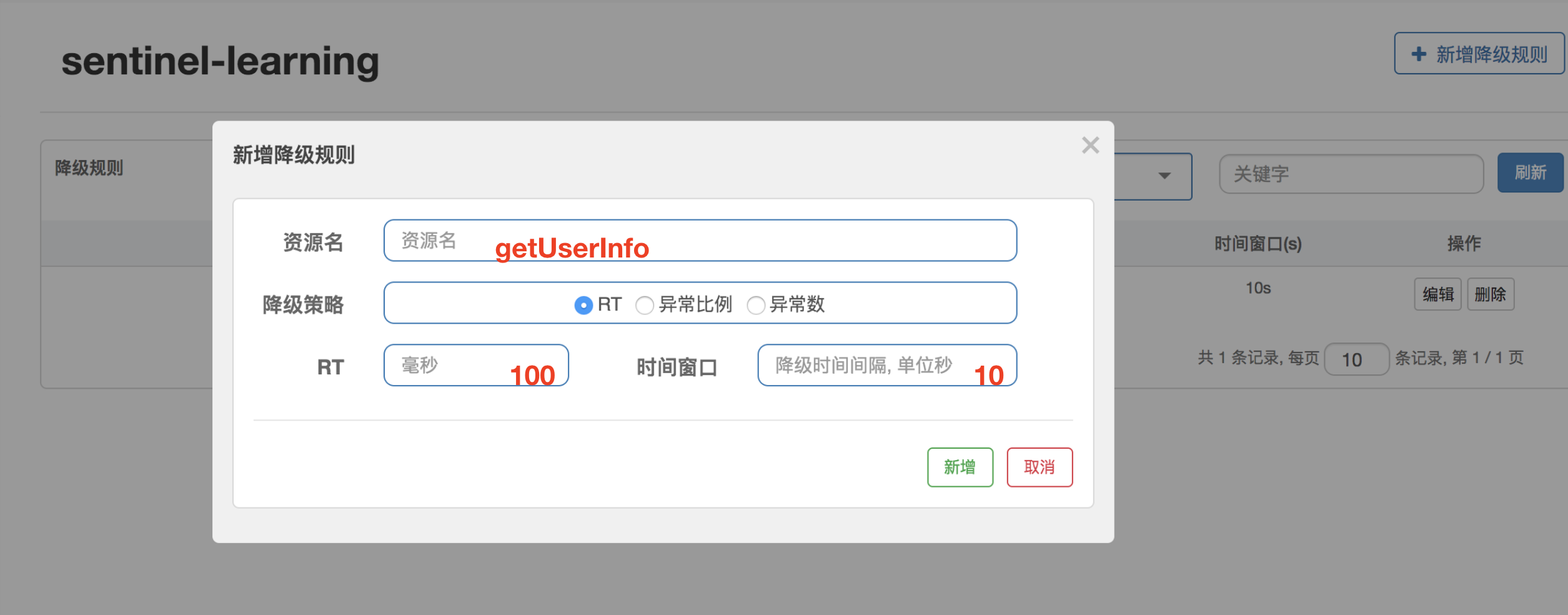
如果按照上面截图所示的配置:对于 getUserInfo 这个资源,正常情况下,它只需要 50ms 就够了,如果它的 RT 超过了 100ms,那么它会进入半降级状态,接下来的 5 次访问,如果都超过了 100ms,那么在接下来的 10 秒内,所有的请求都会被拒绝。
其实这个描述不是百分百准确,打开 DegradeRule#passCheck 源码,我们用代码来描述:
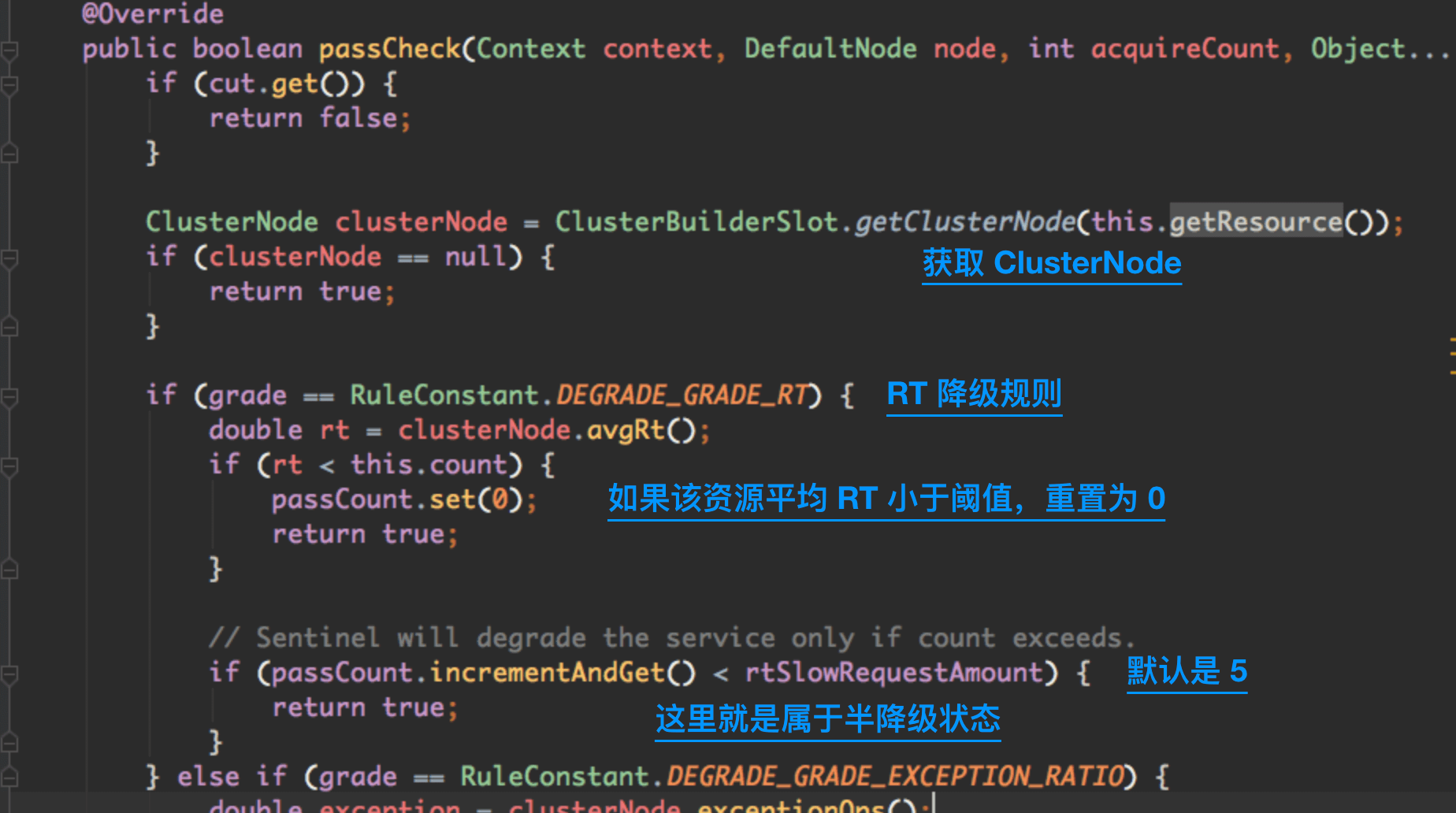
Sentinel 使用了 cut 作为开关,开启这个开关以后,会启动一个定时任务,过了 10秒 以后关闭这个开关。
if (cut.compareAndSet(false, true)) {
ResetTask resetTask = new ResetTask(this);
pool.schedule(resetTask, timeWindow, TimeUnit.SECONDS);
}对于异常比例和异常数的控制,非常简单,大家看一下源码就懂了。同理,达到阈值,开启断路器,之后由定时任务关闭,这里就不浪费篇幅了。
应用和 sentinel-dashboard 的交互
这里花点篇幅介绍一下客户端是怎么和 dashboard 进行交互的。
在 Sentinel 的源码中,打开 sentinel-transport 工程,可以看到三个子工程,common 是基础包和接口定义。

如果客户端要接入 dashboard,可以使用 netty-http 或 simple-http 中的一个。为什么不直接使用 Netty,而要同时提供 http 的选项呢?那是因为你不一定使用 Java 来实现 dashboard,如果我们使用其他语言来实现 dashboard 的话,使用 http 协议比较容易适配。
下面我们只介绍 http 的使用,首先,添加 simple-http 依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-transport-simple-http</artifactId>
<version>1.6.3</version>
</dependency>然后在应用启动参数中添加 dashboard 服务器地址,同时可以指定当前应用的名称:
-Dcsp.sentinel.dashboard.server=127.0.0.1:8080 -Dproject.name=sentinel-learning这个时候我们打开 dashboard 是看不到这个应用的,因为没有注册。
当我们在第一次使用 Sentinel 以后,Sentinel 会自动注册。
下面带大家看看过程是怎样的。首先,我们在使用 Sentinel 的时候会调用 SphU#entry:
public static Entry entry(String name) throws BlockException {
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}这里使用了 Env 类,其实就是这个类做的事情:
public class Env {
public static final Sph sph = new CtSph();
static {
// If init fails, the process will exit.
InitExecutor.doInit();
}
}进到 InitExecutor.doInit 方法:
public static void doInit() {
if (!initialized.compareAndSet(false, true)) {
return;
}
try {
ServiceLoader<InitFunc> loader = ServiceLoader.load(InitFunc.class);
List<OrderWrapper> initList = new ArrayList<OrderWrapper>();
for (InitFunc initFunc : loader) {
insertSorted(initList, initFunc);
}
for (OrderWrapper w : initList) {
w.func.init();
}
// ...
}这里使用 SPI 加载 InitFunc 的实现,大家可以在这里断个点,可以发现这里加载了 CommandCenterInitFunc 类和 HeartbeatSenderInitFunc 类。
前者是客户端启动的接口服务,提供给 dashboard 查询数据和规则设置使用的。后者用于客户端主动发送心跳信息给 dashboard。
我们看 HeartbeatSenderInitFunc#init 方法:
@Override
public void init() {
HeartbeatSender sender = HeartbeatSenderProvider.getHeartbeatSender();
if (sender == null) {
RecordLog.warn("[HeartbeatSenderInitFunc] WARN: No HeartbeatSender loaded");
return;
}
initSchedulerIfNeeded();
long interval = retrieveInterval(sender);
setIntervalIfNotExists(interval);
// 启动一个定时器,发送心跳信息
scheduleHeartbeatTask(sender, interval);
}这里看到,init 方法的第一行就是去加载 HeartbeatSender 的实现类,这里又用到了 SPI 的机制,如果我们添加了 sentinel-transport-simple-http 这个依赖,那么 SimpleHttpHeartbeatSender 就会被加载。
之后在上面的最后一行代码,启动了一个定时器,以一定的间隔(默认10秒)不断地发送心跳信息到 dashboard 应用,这个心跳信息中就包含应用的名称、ip、port、Sentinel 版本 等信息。
而对于 dashboard 来说,有了这些信息,就可以对应用进行规则设置、到应用拉取数据用于页面展示等。
Sentinel 在客户端并没有使用第三方 http 包,而是自己基于 JDK 的 Socket 和 ServerSocket 接口实现了简单的客户端和服务端,主要也是为了不增加依赖。
Sentinel 中秒级 QPS 的统计问题
以下内容建立在你对于滑动窗口有了较为深入的了解的基础上,如果你觉得有点吃力,说明你对于 Sentinel 还不是完全熟悉,可以选择性放弃这一节的内容。
我们前面介绍了滑动窗口用在 分 维度的数据统计上,当我们在说 QPS 的时候,当然我们一般指的是秒维度的数据。当然,你在很多地方看到的 QPS 数据,其实都是通过分维度的数据来得到的,包括 metrics 日志文件、dashboard 中的 QPS。
下面,我们深入分析秒维度数据统计的一些问题。
在开始的时候,我们说了 Sentinel 统计了 分 和 秒 两个维度的数据:
1、对于 分 来说,一轮是 60 秒,分为 60 个时间窗口,每个时间窗口是 1 秒;
2、对于 秒 来说,一轮是 1 秒,分为 2 个时间窗口,每个时间窗口是 0.5 秒;
如果我们用上面介绍的统计分维度的 BucketLeapArray 来统计秒维度数据可以吗?答案当然是不行,因为会不准确。
设想一个场景,我们的一个资源,访问的 QPS 稳定是 10,假设请求是均匀分布的,在相对时间 0.0 - 1.0 秒区间,通过了 10 个请求,我们在 1.1 秒的时候,观察到的 QPS 可能只有 5,因为此时第一个时间窗口被重置了,只有第二个时间窗口有值。
这个大家应该很容易理解,如果你觉得不理解,可以不用浪费时间在这节了
所以,我们可以知道,如果用 BucketLeapArray 来实现,会有 0~50% 的数据误差,这肯定是不能接受的。
那能不能增加窗口的数量来降低误差到一个合理的范围内呢?这个大家可以思考一下,考虑一下它对于性能是否有较大的损失。
大家翻开 StatisticNode 的源码,对于秒维度数据统计,Sentinel 使用下面的构造方法:
// 2 个时间窗口,每个窗口长度 0.5 秒
public ArrayMetric(int sampleCount, int intervalInMs) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
}OccupiableBucketLeapArray 实现类的源码并不长,我们大概看一眼,可以发现它的 newEmptyBucket 和 resetWindowTo 这两个方法和 BucketLeapArray 有点不一样,也就是在重置的时候,它不是直接重置成 0 的。
所以,我们要大胆猜测一下,这个类里面的 borrowArray 做了一些事情,它是 FutureBucketLeapArray 的实例,这个类和前面接触的 BucketLeapArray 差不多,但是加了一个 Future 单词。这里我们先仔细看看它。
它和 BucketLeapArray 唯一的不同是,它覆写了下面这个方法:
@Override
public boolean isWindowDeprecated(long time, WindowWrap<MetricBucket> windowWrap) {
// Tricky: will only calculate for future.
return time >= windowWrap.windowStart();
}我们发现,如果按照它的这种定义,在调用 values() 方法的时候,所有的 2 个窗口都是过期的,将得不到任何的值。所以,我们大概可以判断,给这个数组添加值的时候,使用的时间应该不是当前时间,而是一个未来的时间点。这大概就是 Future 要表达的意思。
我们再回到 OccupiableBucketLeapArray 这个类,可以看到在重置的时候,它使用了 borrowArray 的值:
@Override
protected WindowWrap<MetricBucket> resetWindowTo(WindowWrap<MetricBucket> w, long time) {
// Update the start time and reset value.
w.resetTo(time);
MetricBucket borrowBucket = borrowArray.getWindowValue(time);
if (borrowBucket != null) {
w.value().reset();
w.value().addPass((int)borrowBucket.pass());
} else {
w.value().reset();
}
return w;
}所以我们大概可以猜一猜它是怎么利用这个 FutureBucketLeapArray 实例的:borrowArray 存储了未来的时间窗口的值。当主线到达某个时间窗口的时候,如果发现当前时间窗口是过期的,前面介绍过,会需要重置这个窗口,这个时候,它会检查一下 borrowArray 是否有值,如果有,将其作为这个窗口的初始值填充进来,而不是简单重置为 0 值。
有了这个思路,我们再看 borrowArray 中的值是怎么进来的。
我们很容易可以找到,只可能通过这里的 addWaiting 方法设置:
@Override
public void addWaiting(long time, int acquireCount) {
WindowWrap<MetricBucket> window = borrowArray.currentWindow(time);
window.value().add(MetricEvent.PASS, acquireCount);
}接下来,我们找这个方法被哪里调用了,找到最后,我们发现只有 DefaultController 这个类中有调用。
这个类是流控中的 “快速失败” 规则控制器,我们简单看一下代码:
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
int curCount = avgUsedTokens(node);
if (curCount + acquireCount > count) {
// 只有设置了 prioritized 的情况才会进入到下面的 if 分支
// 也就是说,对于一般的场景,被限流了,就快速失败
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
// 下面的这行 tryOccupyNext 非常复杂,大意就是说去占有"未来的"令牌
// 可以看到,下面做了 sleep,为了保证 QPS 不会因为预占而撑大
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
// 就是这里设置了 borrowArray 的值
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
sleep(waitInMs);
// PriorityWaitException indicates that the request will pass after waiting for {@link @waitInMs}.
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}看到这里,我其实还有很多疑问没有被解开 😂😂😂
首先,这里解开了一个问题,就是这个类为什么叫 OccupiableBucketLeapArray?
- Occupiable 这里代表可以被预占的意思,结合上面 DefaultController 的源码,可以知道它原来是用来满足 prioritized 类型的资源的,我们可以认为这类请求有较高的优先级。如果 QPS 达到阈值,这类资源通常不能用快速失败返回, 而是让它去预占未来的 QPS 容量。
当然,令人失望的是,这里根本没有解开 QPS 是怎么准确计算的这个问题。
下面,我思路倒回来,我来证明 Sentinel 的秒维度的 QPS 统计是不准确的:
public static void main(String[] args) {
// 下面几行代码设置了 QPS 阈值是 100
FlowRule rule = new FlowRule("test");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(100);
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT);
List<FlowRule> list = new ArrayList<>();
list.add(rule);
FlowRuleManager.loadRules(list);
// 先通过一个请求,让 clusterNode 先建立起来
try (Entry entry = SphU.entry("test")) {
} catch (BlockException e) {
}
// 起一个线程一直打印 qps 数据
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println(ClusterBuilderSlot.getClusterNode("test").passQps());
}
}
}).start();
while (true) {
try (Entry entry = SphU.entry("test")) {
Thread.sleep(5);
} catch (BlockException e) {
// ignore
} catch (InterruptedException e) {
// ignore
}
}
}大家跑一下代码,然后观察下输出,QPS 数据在 50~100 这个区间一直变化,印证了我前面说的,秒级 QPS 统计是极度不准确的。
根据前面的分析,其实也没有什么结论要说了。剩下的交给大家自己去思考,去探索,这个过程一定比看我的文章更有意思。
小结
本文比较简单,大家应该很快就可以看完了,欢迎大家反馈阅读感受,有什么需要改进的欢迎提出。
请在评论区提出你碰到的疑问,我会尽量回复你。
0 条评论